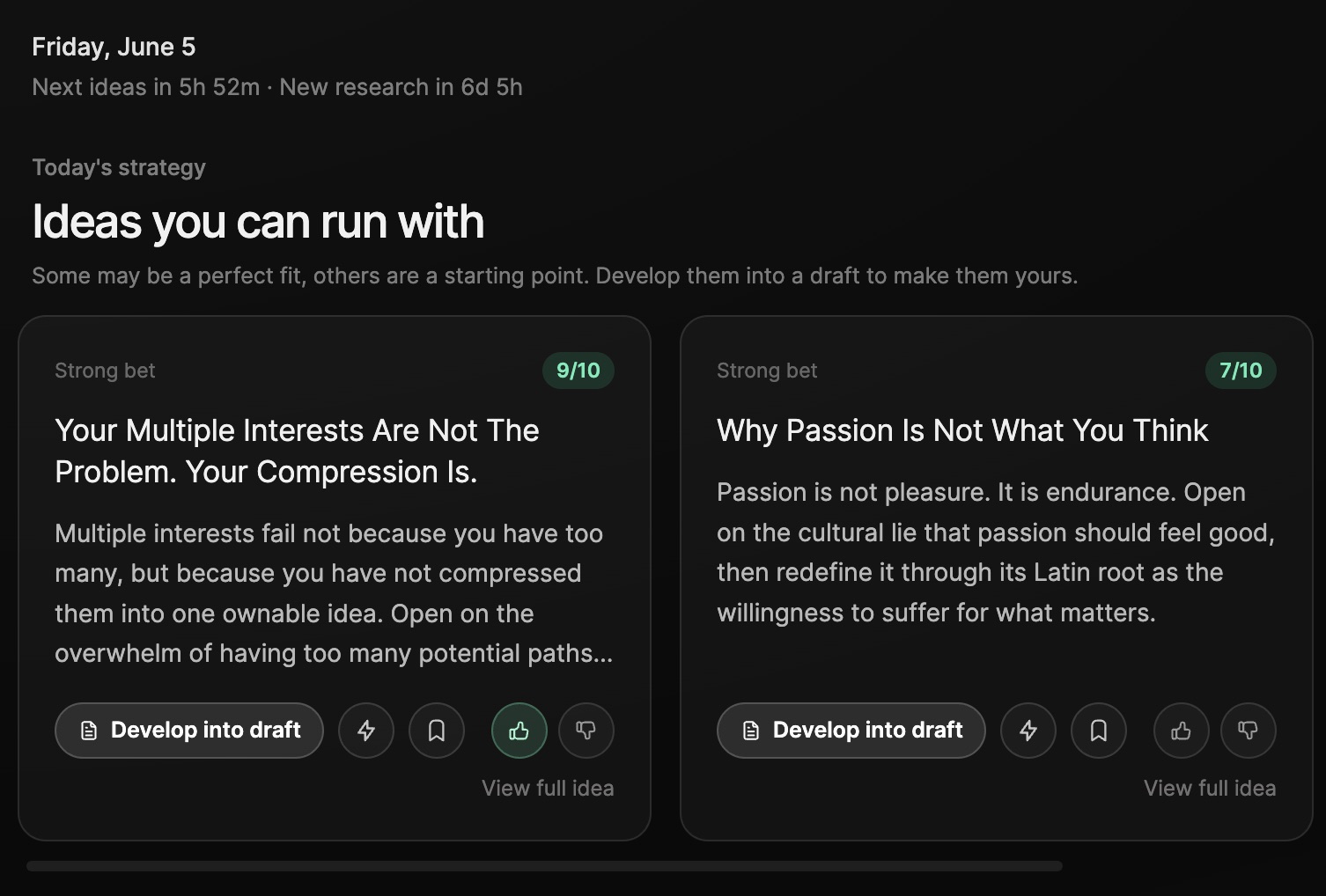
Get a daily brief of validated ideas, made for you.
Eden researches the outliers winning in your niche each week and drips a few execution-ready ideas into your brief every day, each scored against your voice and audience.
Search across 3M+ outliers on any platform, discover your unique identity, and create better content in less than 5 minutes (without sacrificing your authenticity).
"Started using Eden 3 days ago. Engagement across all posts has at least doubled."
Most content tools cover one platform. Eden searches millions of outlier posts across every platform, then lets you save them, study them, and chat with them in one place.
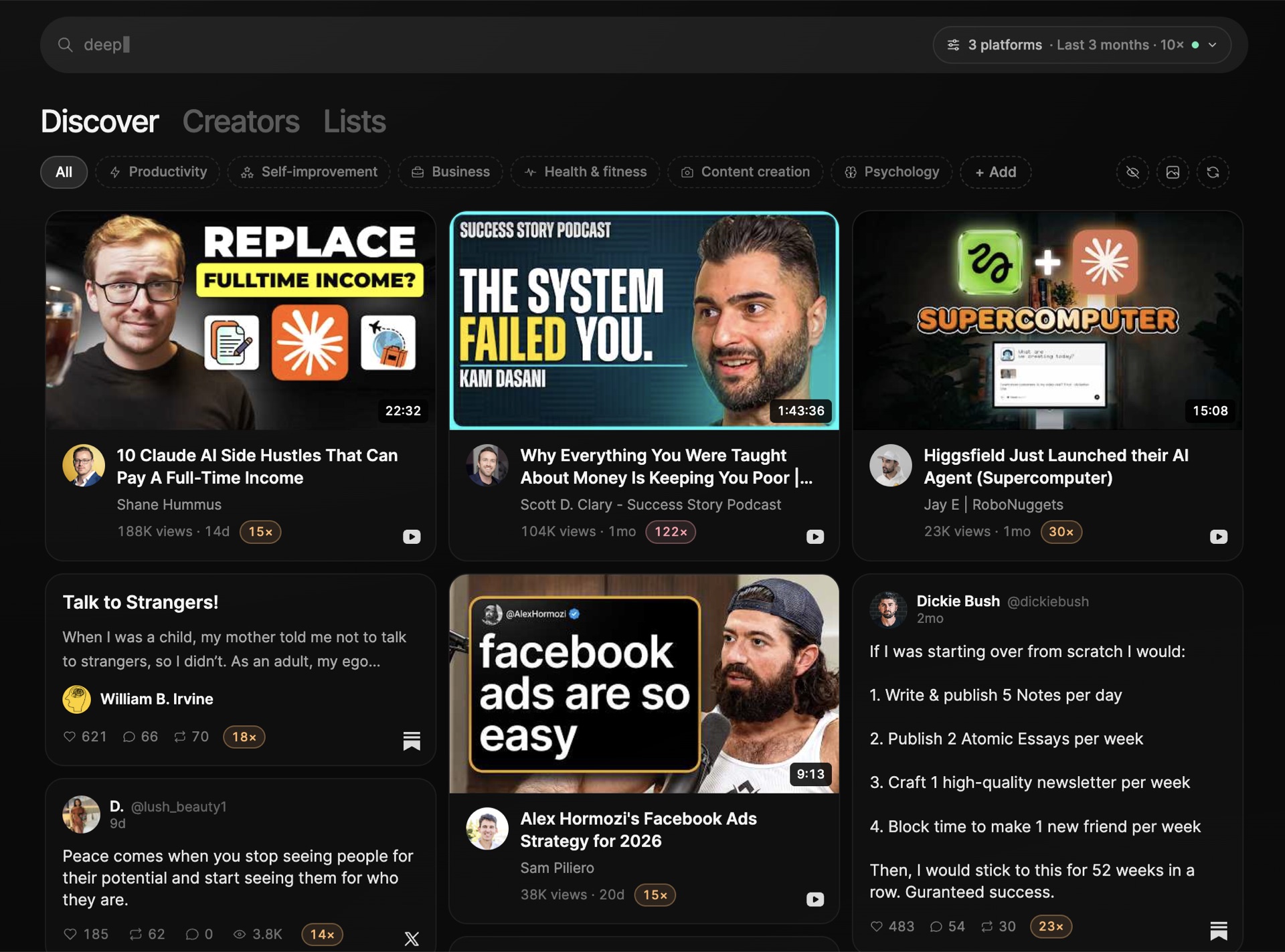
That rarely happens, but when you have an endless supply of proven ideas and write them from your point of view, that's how you grow on social media.
“I cannot wrap my head around how good the discover feature is. Genuinely. My Substack notes engagement has gone up 3-5x. I somehow got 1k newsletter subs over 3 days this past week. YT is at 20k subs and growing.”


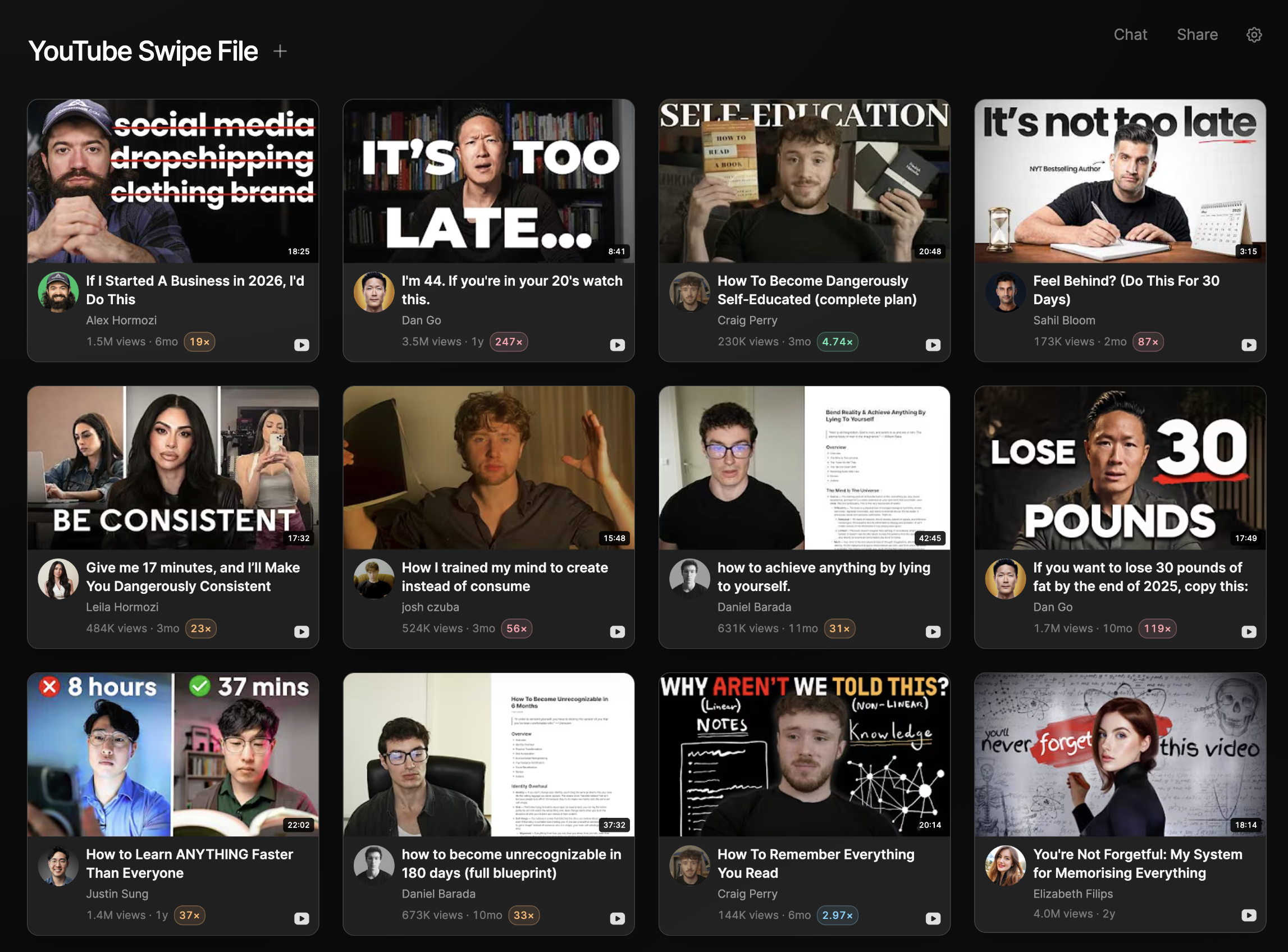
Save from anywhere with the Chrome extension. One click pulls any post, link, or thought off the web and onto a board, source intact. Or drop it straight from chat.
Write where your ideas live. Draft and script right on the board, with your swipe file open beside you.
Chat with them when you need variations. Ask the board for fresh angles and variations, drawn from everything you've saved.
Eden doesn't have to write for you, but if Eden understands you, then it can give you much better ideas than Claude or ChatGPT.
People follow you for your point of view, not your content. Eden draws out the worldview that makes your take different, so it shapes everything you write.
The handful of ideas you keep returning to are the ones people remember you for. Eden helps you name and sharpen them, so they show up across every post.
Most AI flattens you because it copies your words instead of understanding your mind. Eden learns how you think, so what comes back actually sounds like you.
“Finally, you can use your own voice and not sound like ChatGPT.”
Don't know where to start? Just run one of our prompts. They're built to help you come up with ideas and turn them into posts, better than any other chatbot.

Pull up any handle and chat with their whole profile. Break down the hooks, formats, and angles behind their best-performing posts.
Ask for angles working right now and Eden pulls from the outliers already proven across every platform, not a blank-page guess.
Drop a YouTube, X, Instagram, or TikTok link and chat with it directly. No other AI can read a social or video link.
Eden researches the outliers winning in your niche each week and drips a few execution-ready ideas into your brief every day, each scored against your voice and audience.
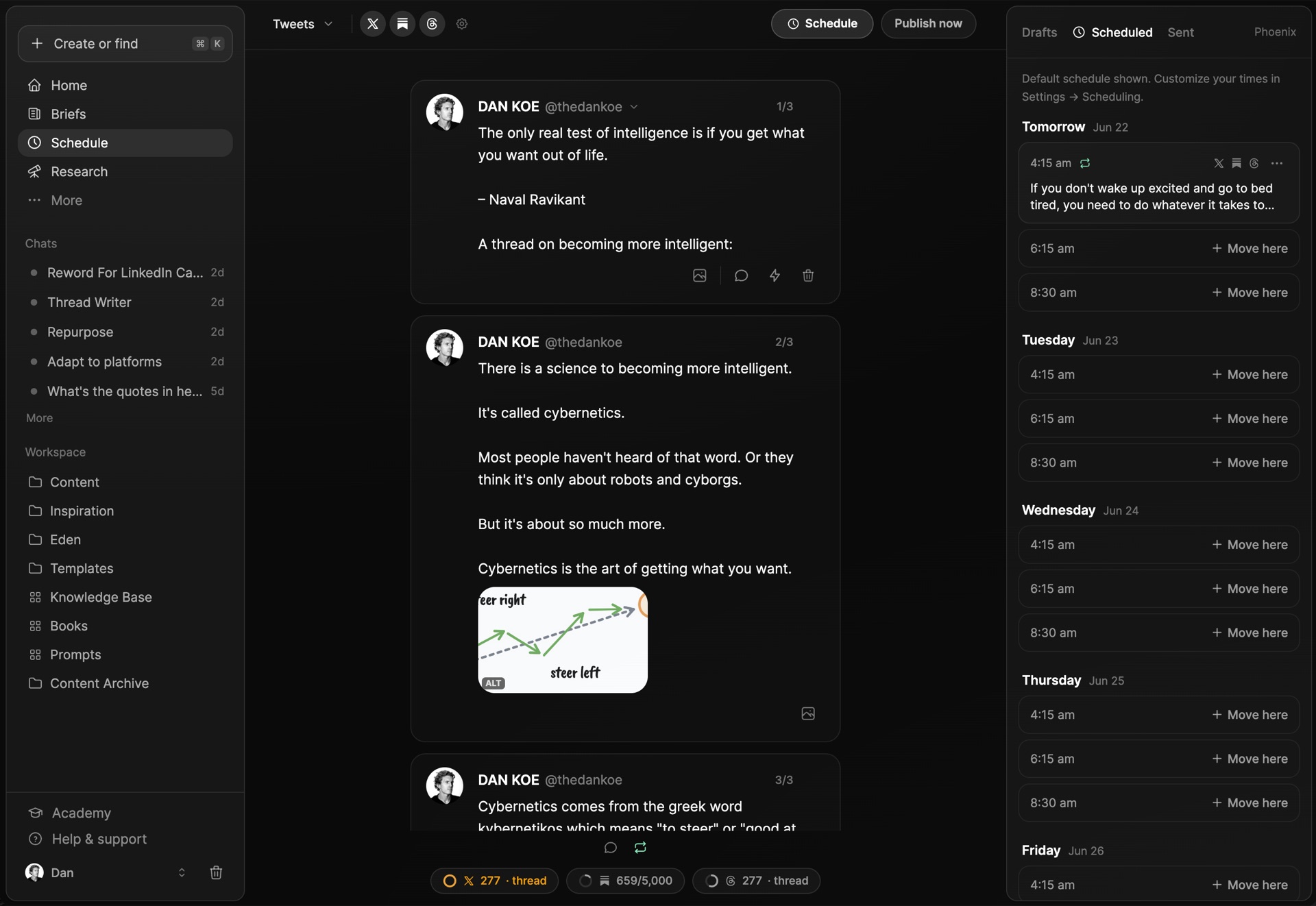
Queue a week of posts in one sitting and Eden ships them to X, Threads, YouTube Shorts, Instagram, TikTok, LinkedIn, Facebook, and Substack, on the best time slots or your own.
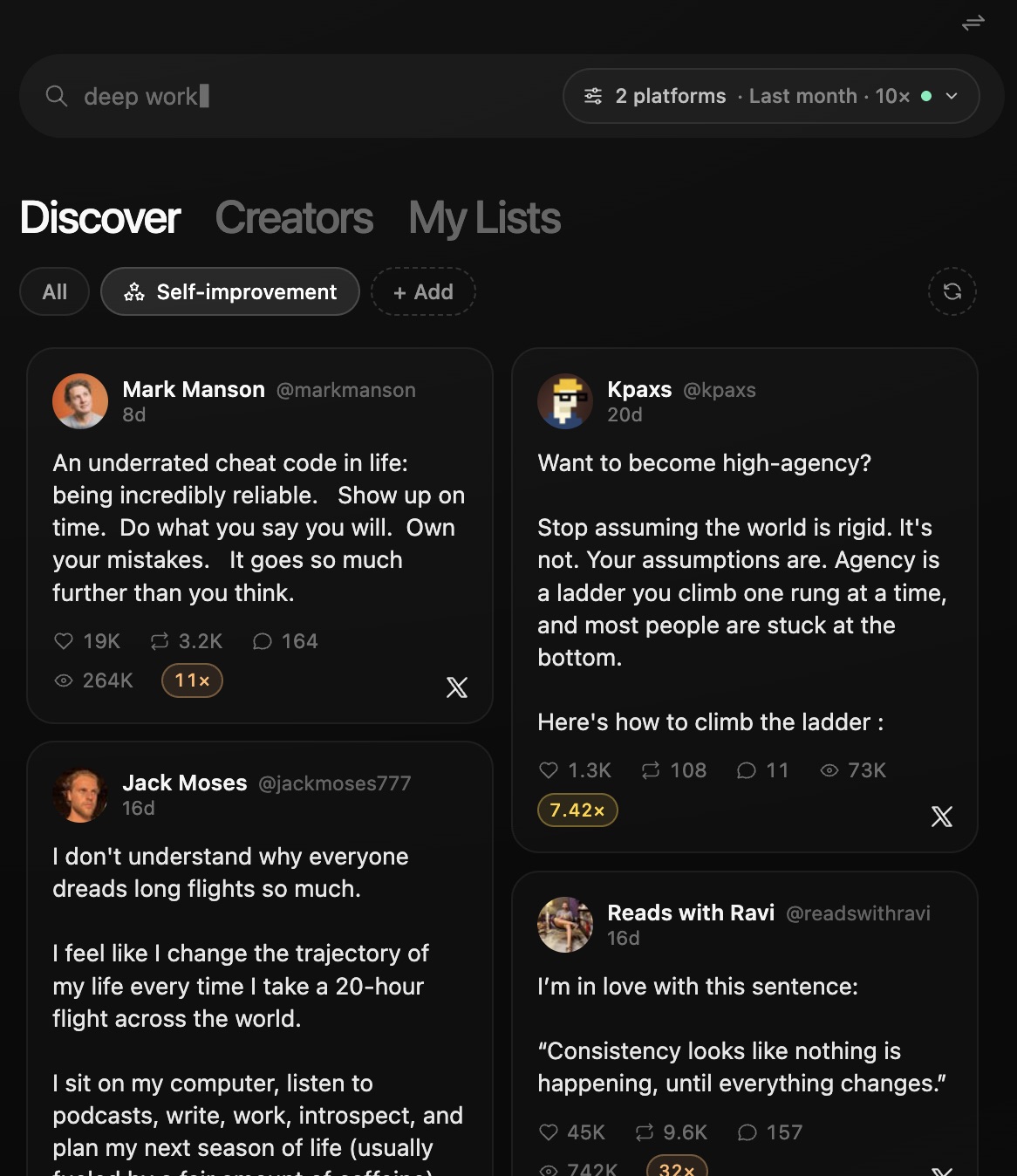
Search 3M+ high-performing posts in your niche across X, Threads, YouTube, Instagram, TikTok, LinkedIn, and Substack. Sort by views, format, or outlier multiplier.
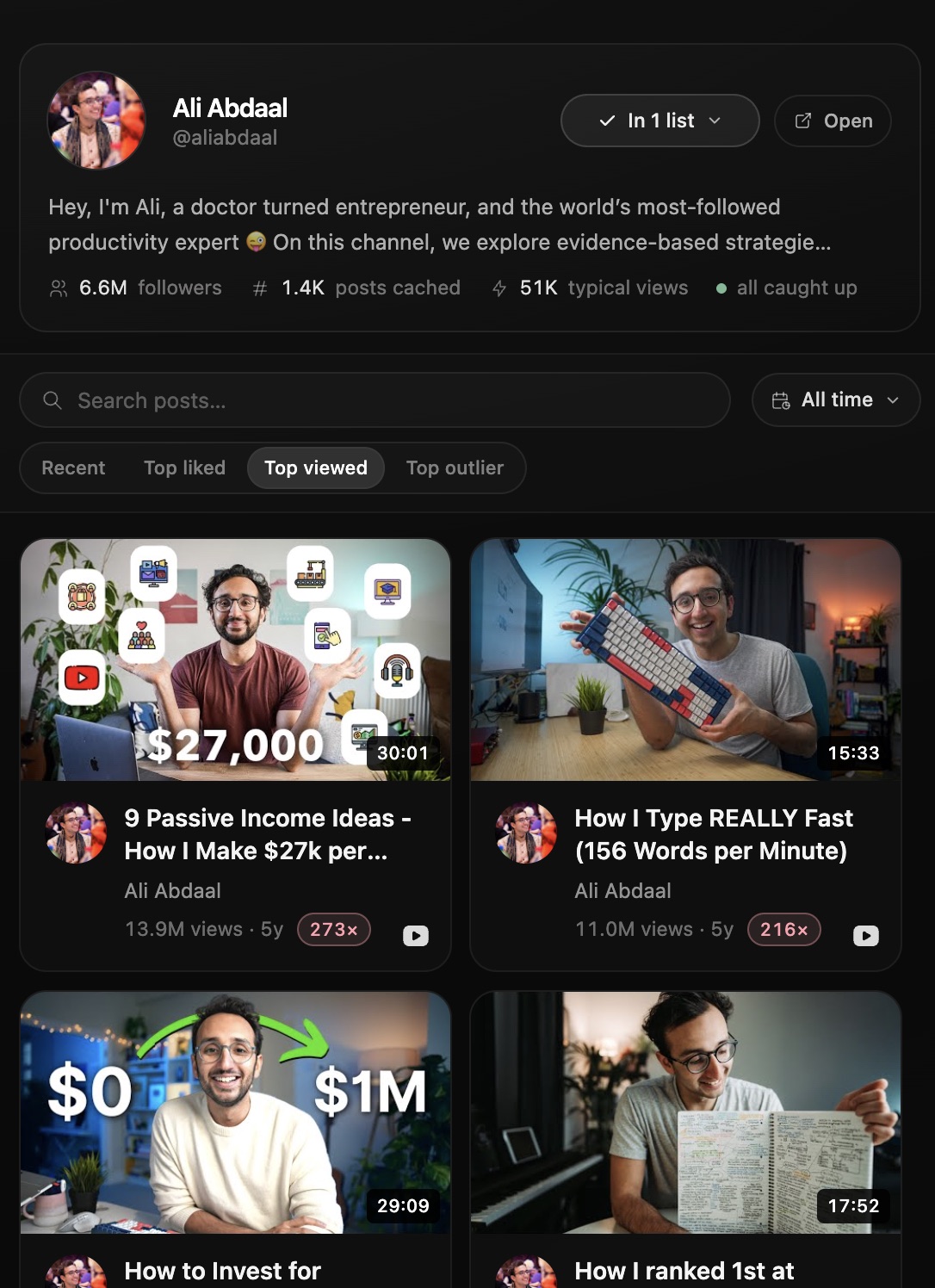
Pick any creator and slice their feed by views, outlier multiplier, or format. Save the wins straight into a list you can pull back open later.
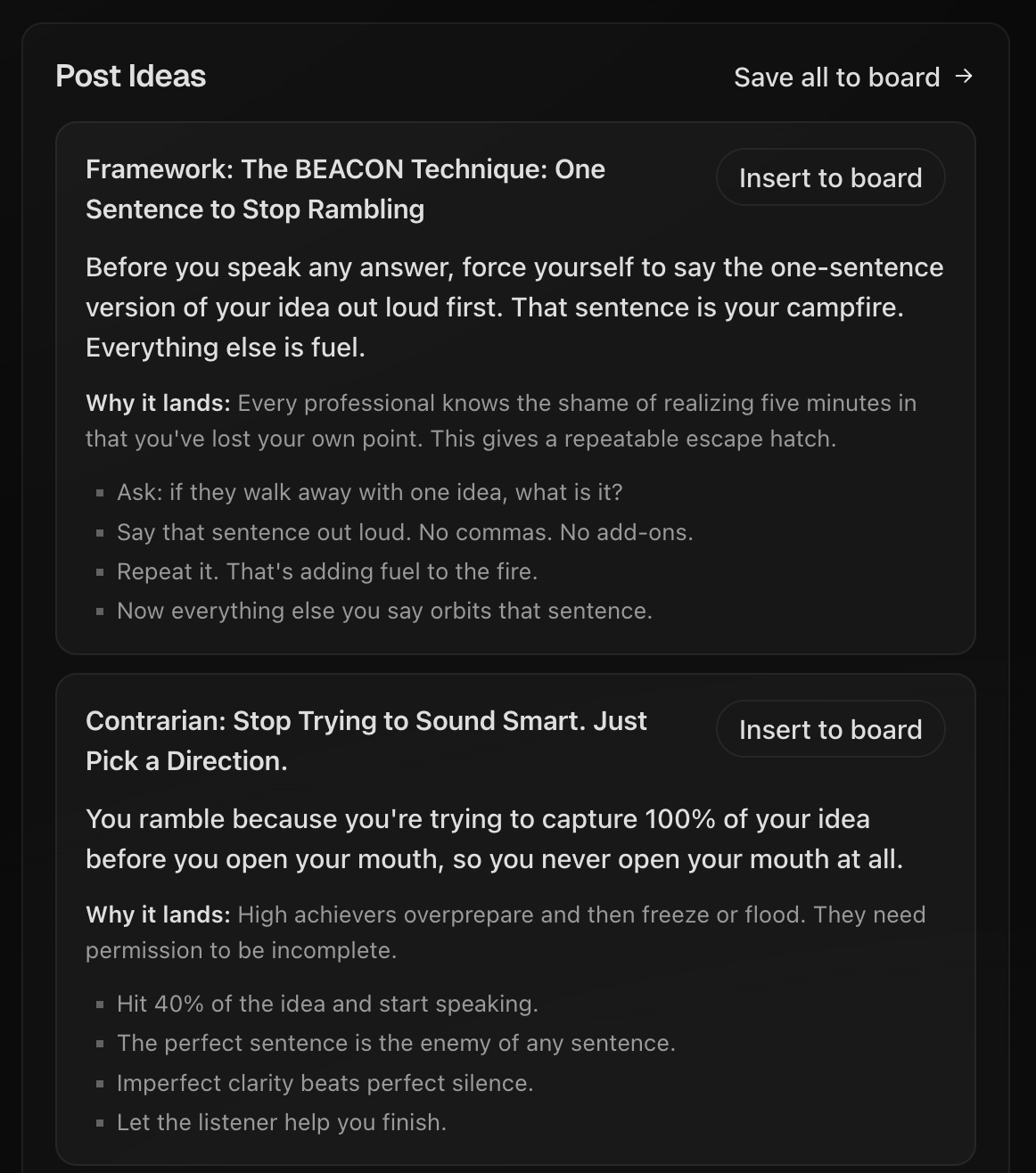
Boost any saved swipe to get variations across formats, lengths, and platforms. A single core idea fills your whole calendar without a second brainstorm.
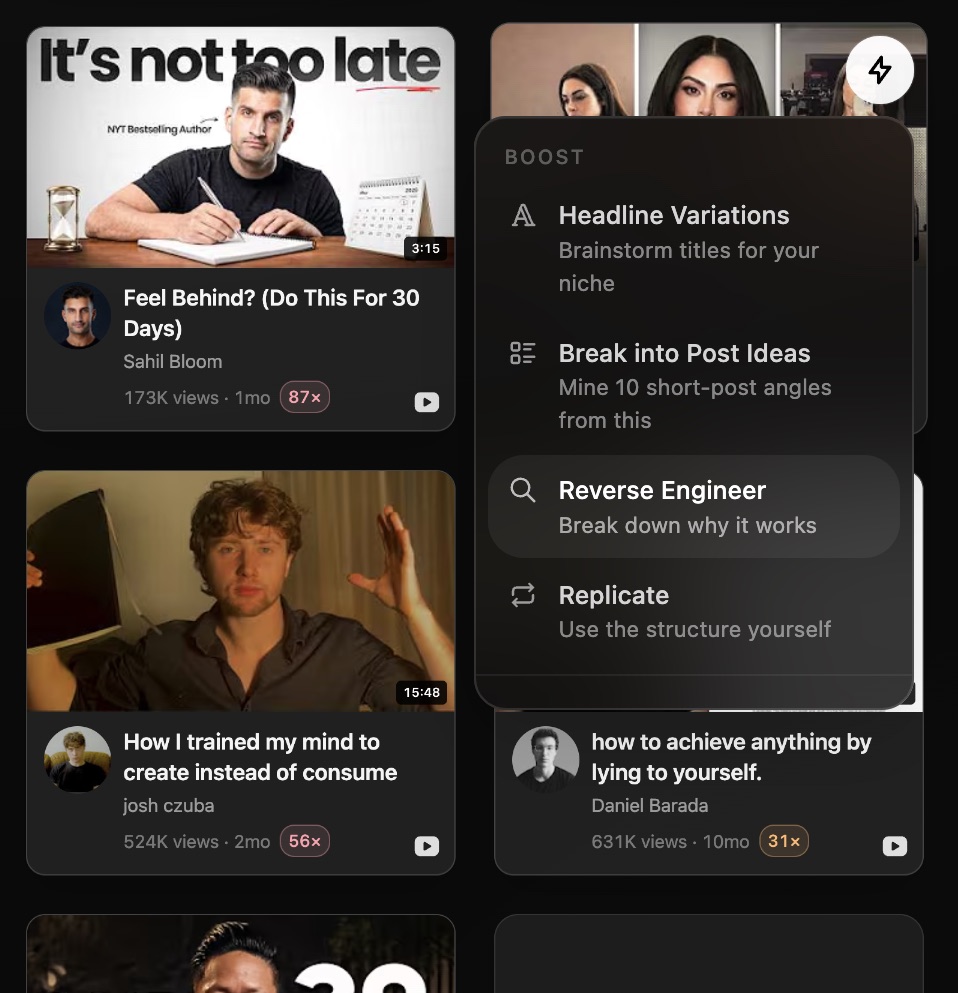
Paste a link, get the structure broken down: hook, beats, payoff. Eden then maps that structure onto your own idea, in your voice.
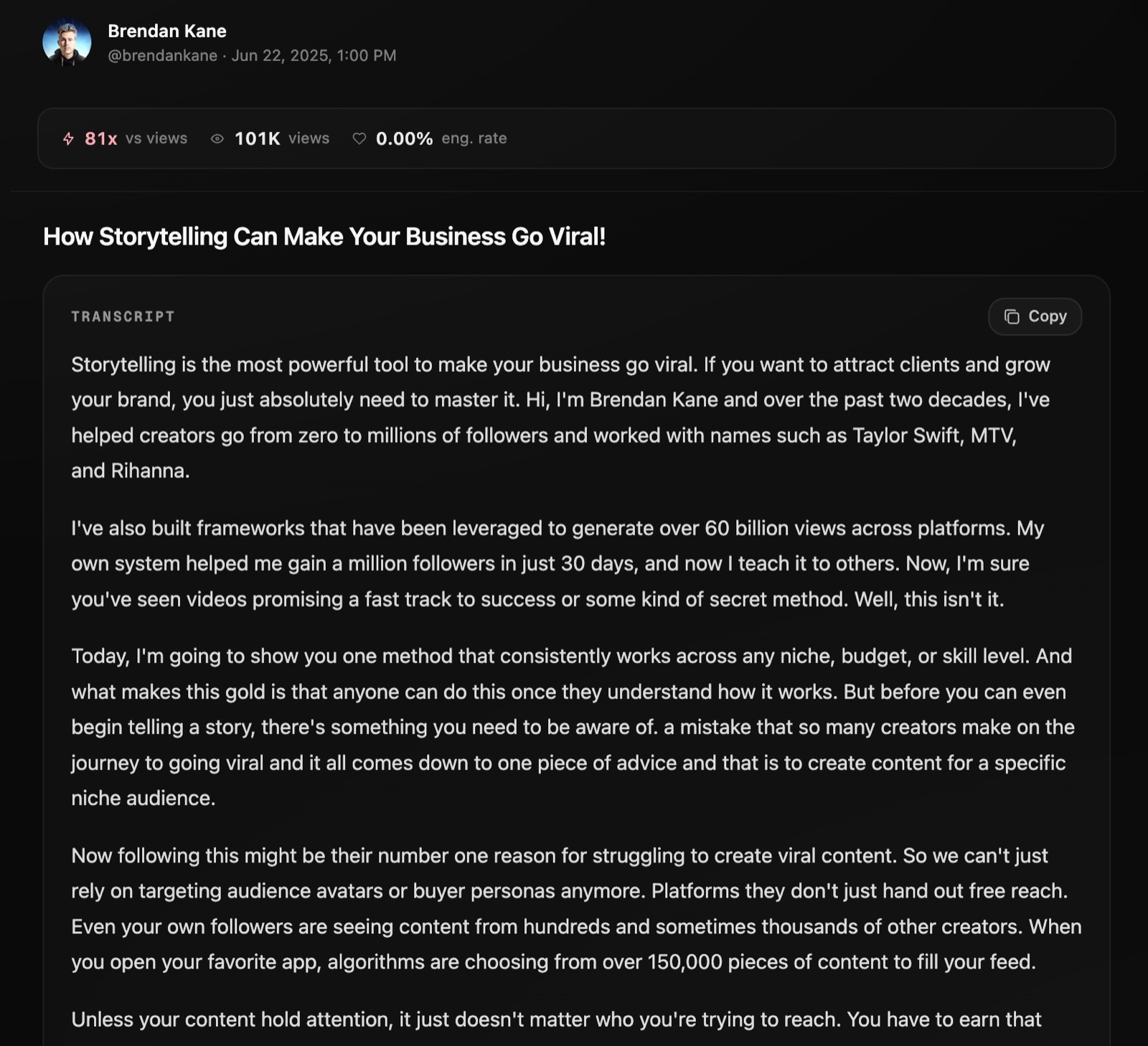
Most AI tools can't read a YouTube video, a TikTok, or an Instagram reel. Eden transcribes anything you save, so you can chat with it, break it down, or remix it in your voice.
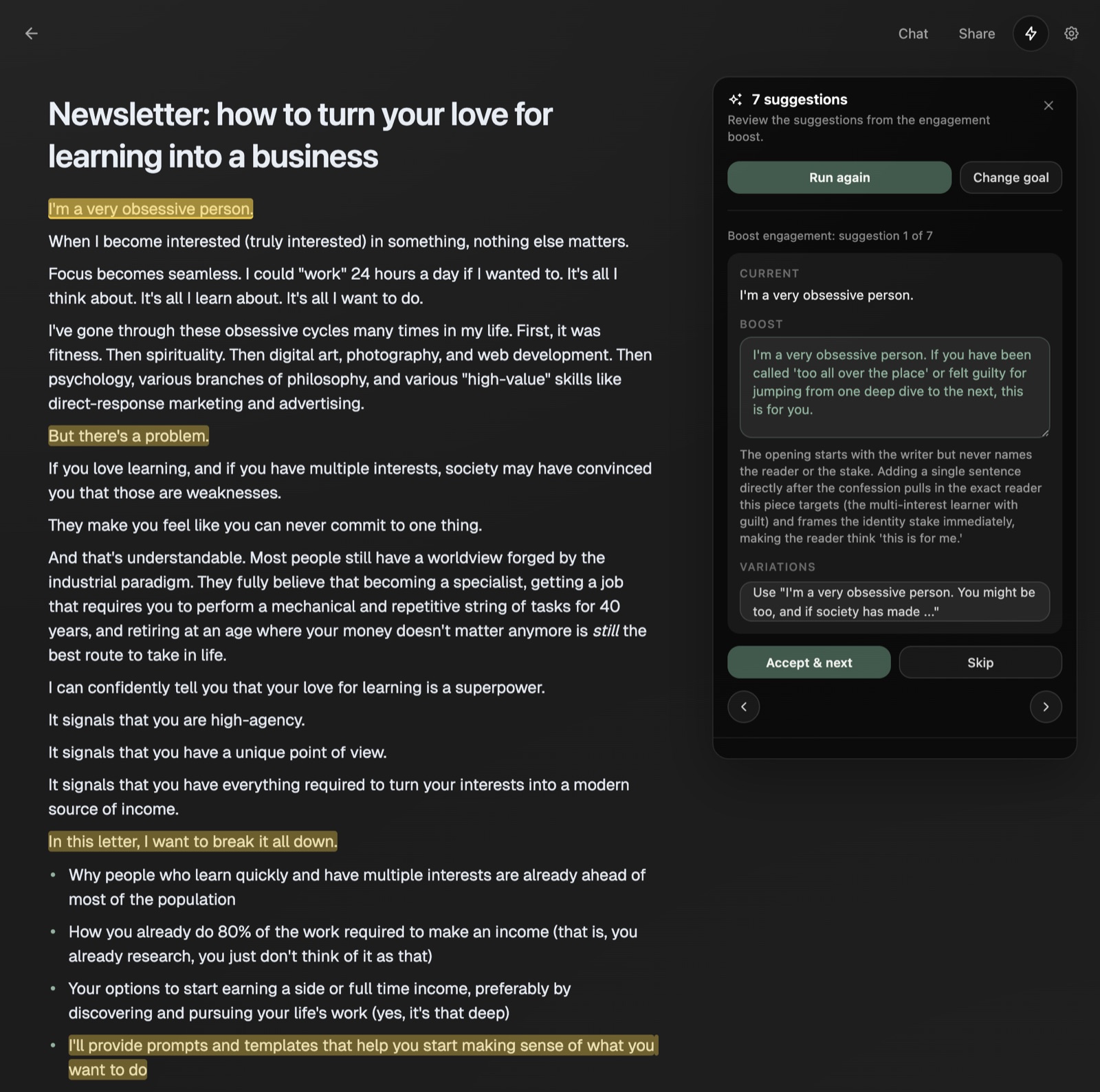
Outline, script, and draft in a single editor. Your swipe files and saved ideas sit one click away the whole time, so the page is never blank.
Writing content changed my life. Over the past few years I've built a following in the millions, written two books, published the most-viewed article in X history (was paid $250,000 for it), and made life-changing money from words on a screen.
Eden is everything I learned, built into the tool I wish I had when I started.
After the trial, your account drops to a free plan. Upgrade only when you feel like Eden has earned its keep in your workflow.
Annual plans include the AI content bootcamp, free with Pro or Studio.
If you're trying to show up consistently with ideas worth posting.
If every post needs to perform.
If your team runs content at scale.
Need to bring teammates? Add team members for $15/month per seat ($150/year on annual plans) on any tier, prorated to the day.
Connect Eden to Claude, ChatGPT, or other agents. Research top posts on any platform, breakdown creator's profiles, and replicate what works in your voice.
Use Eden to search for top performing productivity posts on Instagram.. Find the best hooks for AI content on X, then rewrite them using my Eden identity.. Find Alex Hormozi's best YouTube videos and give me a full breakdown on why they work.. I want to write a Substack article, research the best ones on psychology and give me some ideas.
Try it for free. Downgrades to a free boards plan if you don't upgrade.
Start free